
Grokking is the mysterious phenomenon of explosive machine learning.
Learn more:
QUICK STUDY on Twitter.
A Mechanistic Interpretability Analysis of Grokking by Neel Nanda, Tom Lieberum. 15th Aug 2022
Introduction
Grokking is a recent phenomena discovered by OpenAI researchers, that in my opinion is one of the most fascinating mysteries in deep learning. That models trained on small algorithmic tasks like modular addition will initially memorise the training data, but after a long time will suddenly learn to generalise to unseen data.
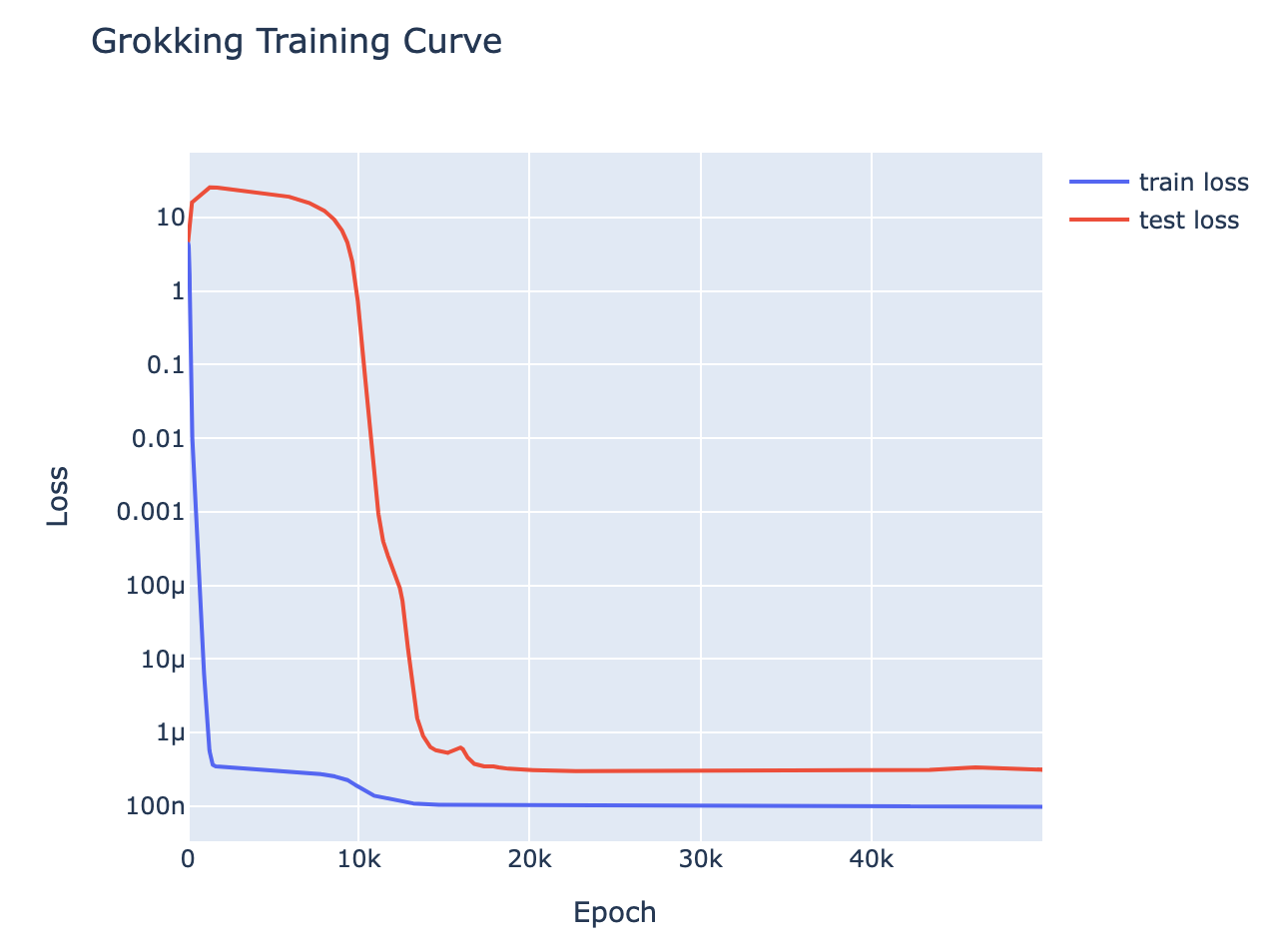
A training curve for a 1L Transformer trained to do addition mod 113, trained on 30% of the pairs – it shows clear grokking This is a write-up of an independent research project I did into understanding grokking through the lens of mechanistic interpretability. My most important claim is that grokking has a deep relationship to phase changes. Phase changes, ie a sudden change in the model’s performance for some capability during training, are a general phenomena that occur when training models, that have also been observed in large models trained on non-toy tasks. For example, the sudden change in a transformer’s capacity to do in-context learning when it forms induction heads. In this work examine several toy settings where a model trained to solve them exhibits a phase change in test loss, regardless of how much data it is trained on. I show that if a model is trained on these limited data with high regularisation, then that the model shows grokking.
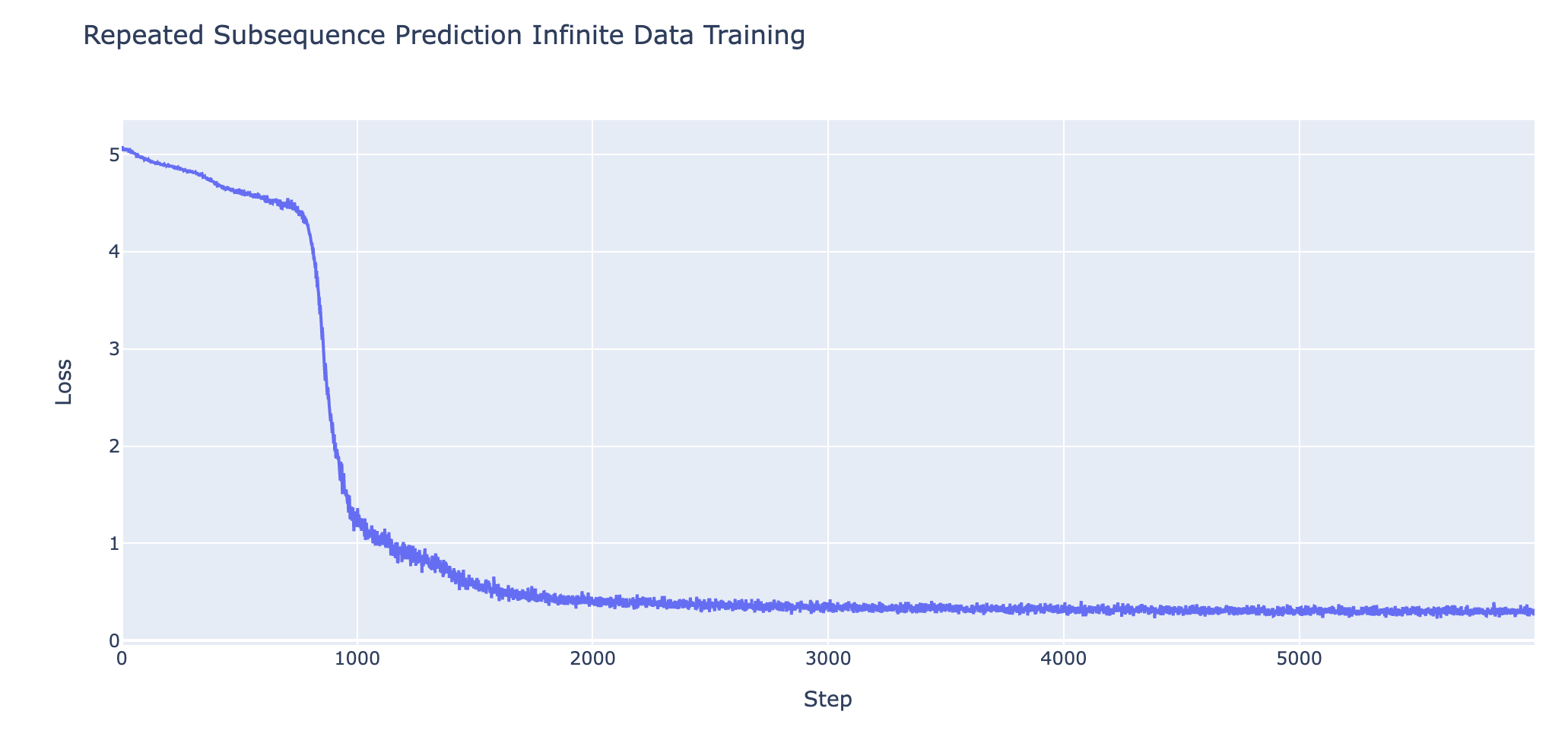
Loss curve for predicting repeated subsequences in a sequence of random tokens in a 2L attention only transformer on infinite data – shows a phase change 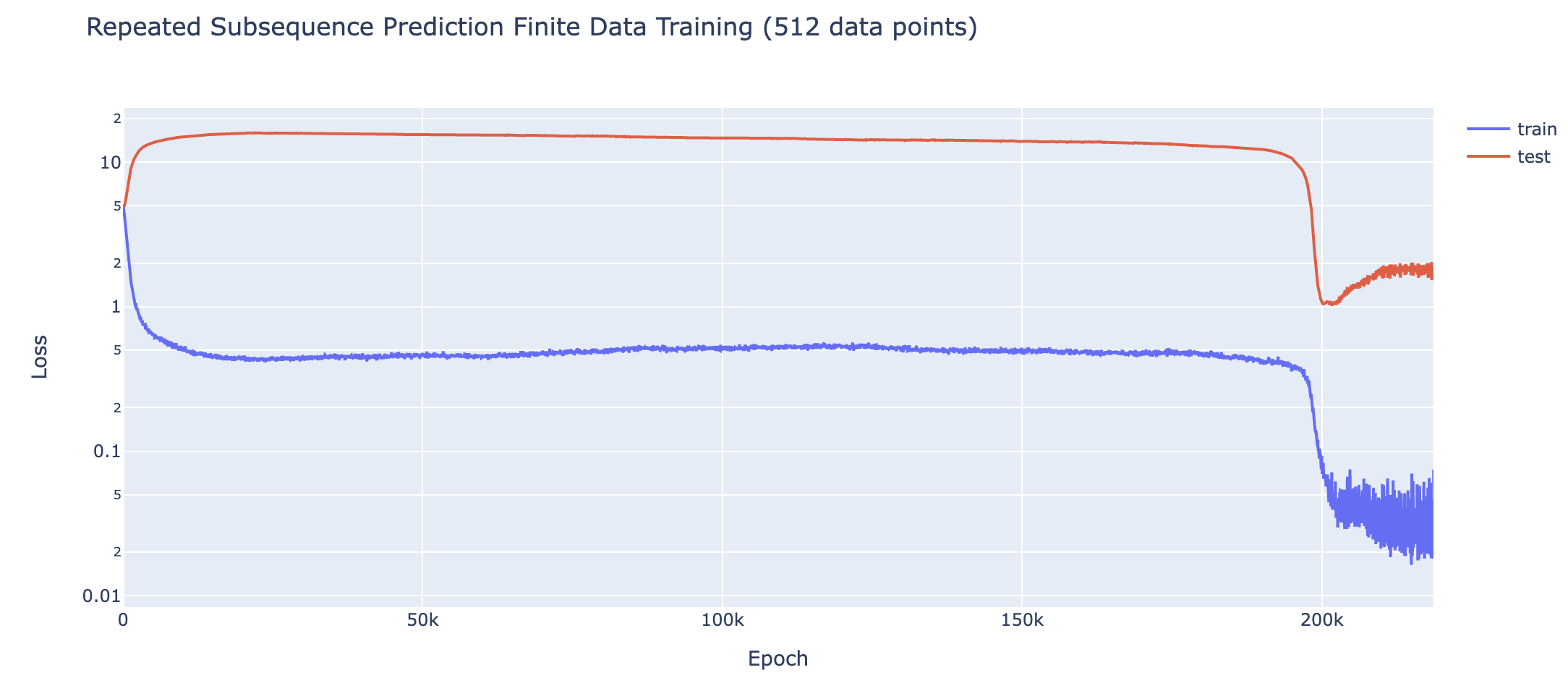
Loss curve for predicting repeated subsequences in a sequence of random tokens in a 2L attention-only transformer given 512 training data points – shows clear grokking. One of the core claims of mechanistic interpretability is that neural networks can be understood, that rather than being mysterious black boxes they learn interpretable algorithms which can be reverse engineered and comprehended. This work serves as a proof of concept of that, and that reverse engineering models is key to understanding them. I fully reverse engineer the inferred algorithm from a transformer that has grokked how to do modular addition (which somehow involves Discrete Fourier Transforms and trig identities?!), and use this as a concrete example to analyse what happens during training to understand what happened during grokking. I close with discussion and thoughts on the alignment relevance of these results.
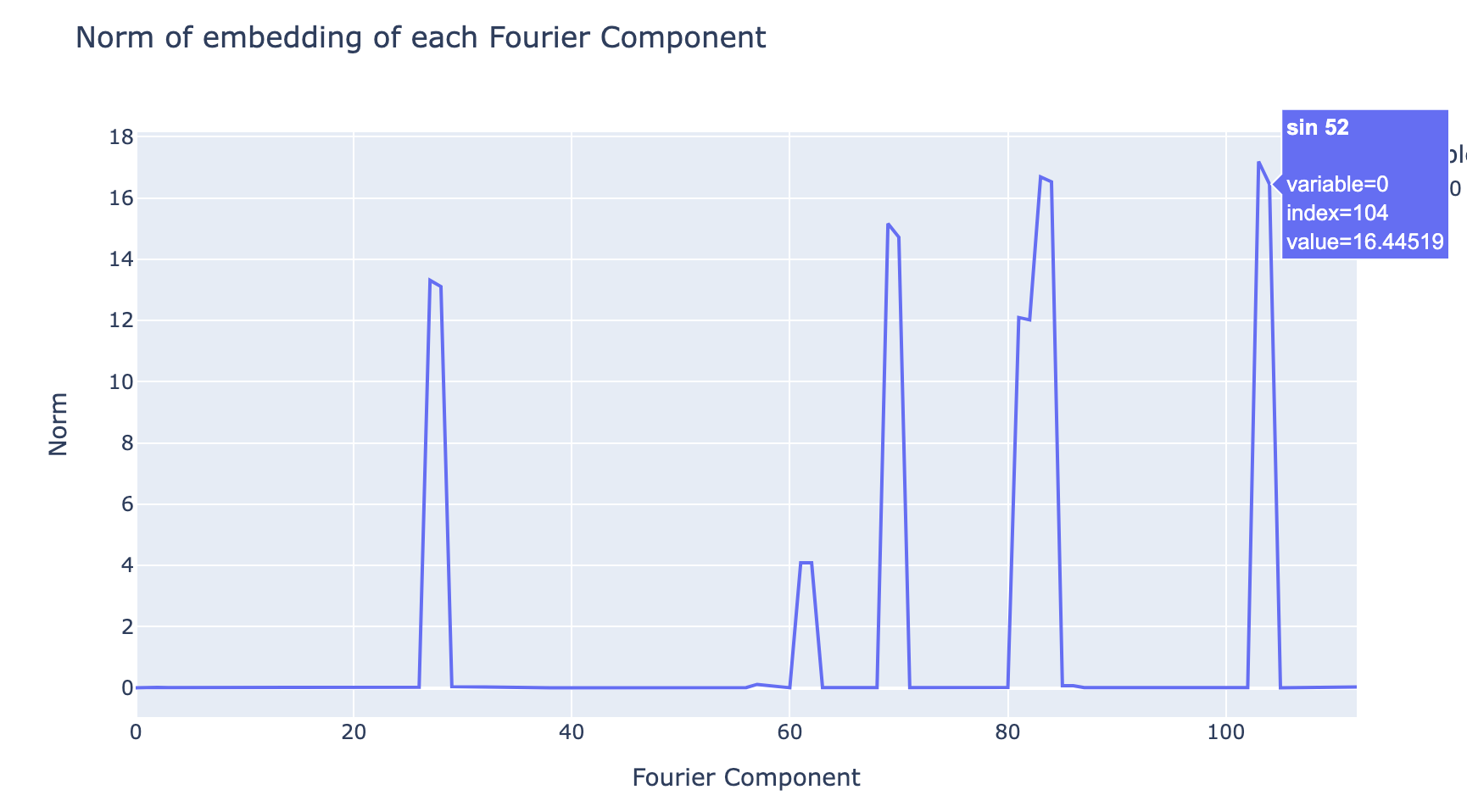
Norm of rows of the embedding matrix for modular addition, after applying a Discrete Fourier Transform to the input space – the sparsity shows that the model is paying attention to some frequencies of waves but not others, and thus is operating in the space of waves of different frequencies. This is accompanied by a paper in the form of a Colab notebook containing the code for this project, a lot of interactive graphics, and much more in-depth discussion and technical details. In this write-up I try to give a high-level conceptual overview of the claims and the most compelling results and evidence, I refer you to the notebook if you want the full technical details.
This write-up ends with a list of ideas for future directions of this research. I think this is a particularly exciting problem to start with if you want to get into mechanistic interpretability since it’s concrete, only involves tiny models, and is easy to do in a Colab notebook. If you might want to work on some of these, please reach out! In particular, I’m looking to hire an intern/research assistant, and if you’re excited about these future directions you might be a good fit.
Progress measures for grokking via mechanistic interpretability
ABSTRACT. Neural networks often exhibit emergent behavior, where qualitatively new capabilities arise from scaling up the amount of parameters, training data, or training steps. One approach to understanding emergence is to find continuous \textit{progress measures} that underlie the seemingly discontinuous qualitative changes. We argue that progress measures can be found via mechanistic interpretability: reverse-engineering learned behaviors into their individual components. As a case study, we investigate the recently-discovered phenomenon of “grokking” exhibited by small transformers trained on modular addition tasks. We fully reverse engineer the algorithm learned by these networks, which uses discrete Fourier transforms and trigonometric identities to convert addition to rotation about a circle. We confirm the algorithm by analyzing the activations and weights and by performing ablations in Fourier space. Based on this understanding, we define progress measures that allow us to study the dynamics of training and split training into three continuous phases: memorization, circuit formation, and cleanup. Our results show that grokking, rather than being a sudden shift, arises from the gradual amplification of structured mechanisms encoded in the weights, followed by the later removal of memorizing components.