Can AI Scaling Continue Through 2030? We investigate the scalability of AI training runs.
We identify electric power, chip manufacturing, data and latency as constraints. We conclude that 2e29 FLOP training runs will likely be feasible by 2030.
Introduction
In recent years, the capabilities of AI models have significantly improved. Our research suggests that this growth in computational resources accounts for a significant portion of AI performance improvements.1 The consistent and predictable improvements from scaling have led AI labs to aggressively expand the scale of training, with training compute expanding at a rate of approximately 4x per year.
To put this 4x annual growth in AI training compute into perspective, it outpaces even some of the fastest technological expansions in recent history. It surpasses the peak growth rates of mobile phone adoption (2x/year, 1980-1987), solar energy capacity installation (1.5x/year, 2001-2010), and human genome sequencing (3.3x/year, 2008-2015).
Here, we examine whether it is technically feasible for the current rapid pace of AI training scaling—approximately 4x per year—to continue through 2030. We investigate four key factors that might constrain scaling: power availability, chip manufacturing capacity, data scarcity, and the “latency wall”, a fundamental speed limit imposed by unavoidable delays in AI training computations.
Our analysis incorporates the expansion of production capabilities, investment, and technological advancements. This includes, among other factors, examining planned growth in advanced chip packaging facilities, construction of additional power plants, and the geographic spread of data centers to leverage multiple power networks. To account for these changes, we incorporate projections from various public sources: semiconductor foundries’ planned expansions, electricity providers’ capacity growth forecasts, other relevant industry data, and our own research.
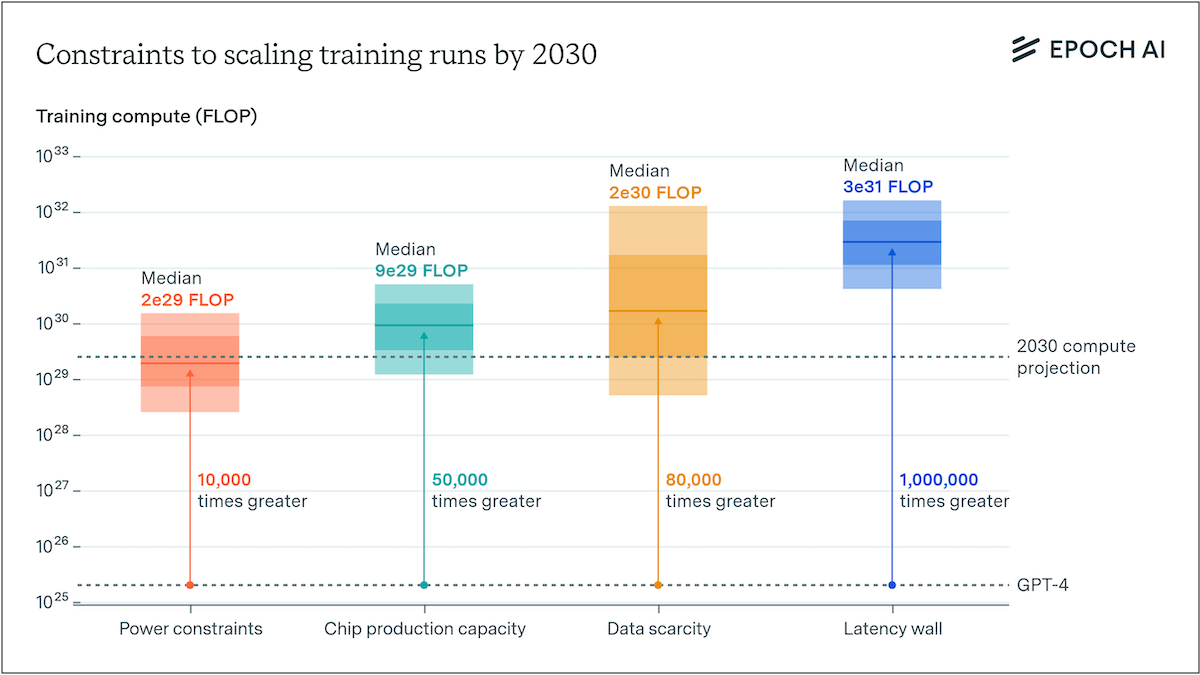
We find that training runs of 2e29 FLOP will likely be feasible by the end of this decade. In other words, by 2030 it will be very likely possible to train models that exceed GPT-4 in scale to the same degree that GPT-4 exceeds GPT-2 in scale.2 If pursued, we might see by the end of the decade advances in AI as drastic as the difference between the rudimentary text generation of GPT-2 in 2019 and the sophisticated problem-solving abilities of GPT-4 in 2023.
Whether AI developers will actually pursue this level of scaling depends on their willingness to invest hundreds of billions of dollars in AI expansion over the coming years. While we briefly discuss the economics of AI investment later, a thorough analysis of investment decisions is beyond the scope of this report.
For each bottleneck we offer a conservative estimate of the relevant supply and the largest training run they would allow.3 Throughout our analysis, we assume that training runs could last between two to nine months, reflecting the trend towards longer durations. We also assume that when distributing AI data center power for distributed training and chips companies will only be able to muster about 10% to 40% of the existing supply.4
Power constraints. Plans for data center campuses of 1 to 5 GW by 2030 have already been discussed, which would support training runs ranging from 1e28 to 3e29 FLOP (for reference, GPT-4 was likely around 2e25 FLOP). Geographically distributed training could tap into multiple regions’ energy infrastructure to scale further. Given current projections of US data center expansion, a US distributed network could likely accommodate 2 to 45 GW, which assuming sufficient inter-data center bandwidth would support training runs from 2e28 to 2e30 FLOP. Beyond this, an actor willing to pay the costs of new power stations could access significantly more power, if planning 3 to 5 years in advance.
Chip manufacturing capacity. AI chips provide the compute necessary for training large AI models. Currently, expansion is constrained by advanced packaging and high-bandwidth memory production capacity. However, given the scale-ups planned by manufacturers, as well as hardware efficiency improvements, there is likely to be enough capacity for 100M H100-equivalent GPUs to be dedicated to training to power a 9e29 FLOP training run, even after accounting for the fact that GPUs will be split between multiple AI labs, and in part dedicated to serving models. However, this projection carries significant uncertainty, with our estimates ranging from 20 million to 400 million H100 equivalents, corresponding to 1e29 to 5e30 FLOP (5,000 to 300,000 times larger than GPT-4).
Data scarcity. Training large AI models requires correspondingly large datasets. The indexed web contains about 500T words of unique text, and is projected to increase by 50% by 2030. Multimodal learning from image, video and audio data will likely moderately contribute to scaling, plausibly tripling the data available for training. After accounting for uncertainties on data quality, availability, multiple epochs, and multimodal tokenizer efficiency, we estimate the equivalent of 400 trillion to 20 quadrillion tokens available for training by 2030, allowing for 6e28 to 2e32 FLOP training runs. We speculate that synthetic data generation from AI models could increase this substantially.
Latency wall. The latency wall represents a sort of “speed limit” stemming from the minimum time required for forward and backward passes. As models scale, they require more sequential operations to train. Increasing the number of training tokens processed in parallel (the ‘batch size’) can amortize these latencies, but this approach has a limit. Beyond a ‘critical batch size’, further increases in batch size yield diminishing returns in training efficiency, and training larger models requires processing more batches sequentially. This sets an upper bound on training FLOP within a specific timeframe. We estimate that cumulative latency on modern GPU setups would cap training runs at 3e30 to 1e32 FLOP. Surpassing this scale would require alternative network topologies, reduced communication latencies, or more aggressive batch size scaling than currently feasible.
Bottom line. While there is substantial uncertainty about the precise scales of training that are technically feasible, our analysis suggests that training runs of around 2e29 FLOP are likely possible by 2030. This represents a significant increase in scale over current models, similar to the size difference between GPT-2 and GPT-4. The constraint likely to bind first is power, followed by the capacity to manufacture enough chips. Scaling beyond would require vastly expanded energy infrastructure and the construction of new power plants, high-bandwidth networking to connect geographically distributed data centers, and a significant expansion in chip production capacity.