Hey! Be VERY careful what you wish for! What happens when you succeed to build AGI???
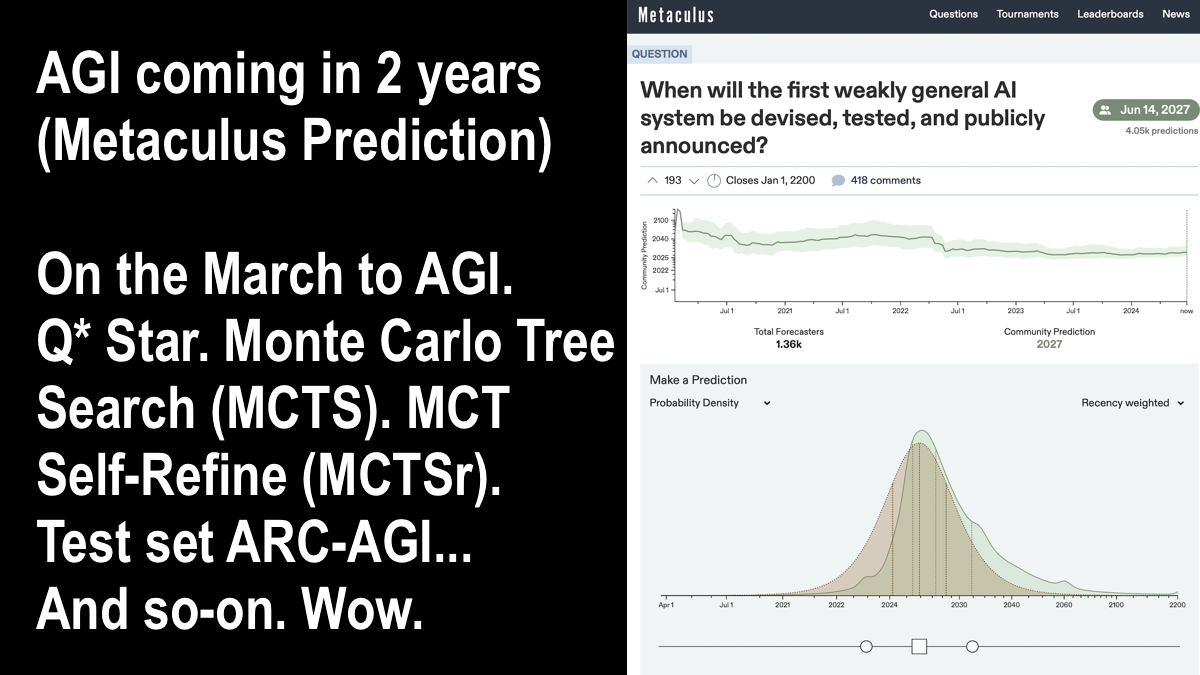
AGI coming in 2 years (Metaculus): When will the first weakly general AI system be devised, tested, and publicly announced?
On the March to AGI with Q* Star and Monte Carlo Tree Search (MCTS) and MCT Self-Refine (MCTSr) and test set ARC-AGI. Wow.
It’s finally here. Q* rings true. Tiny LLMs are as good at math as a frontier model.
By using the same techniques Google used to solve Go (MTCS and backprop), Llama8B gets 96.7% on math benchmark GSM8K!
That’s better than GPT-4, Claude and Gemini, with 200x less parameters! pic.twitter.com/ajpEJlqvtD
— Deedy (@deedydas) June 15, 2024
Learn more
Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B. A Technical Report. – 13 JUNE 2024
- Abstract. This paper introduces the MCT Self-Refine (MCTSr) algorithm, an innovative integration of Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS), designed to enhance performance in complex mathematical reasoning tasks. Addressing the challenges of accuracy and reliability in LLMs, particularly in strategic and mathematical reasoning, MCTSr leverages systematic exploration and heuristic self-refine mechanisms to improve decision-making frameworks within LLMs. The algorithm constructs a Monte Carlo search tree through it- erative processes of Selection, self-refine, self-evaluation, and Backpropagation, utilizing an improved Upper Confidence Bound (UCB) formula to optimize the exploration-exploitation balance. Extensive experiments demonstrate MCTSr’s efficacy in solving Olympiad-level mathematical problems, significantly improving success rates across multiple datasets, including GSM8K, GSM Hard, MATH, and Olympiad-level benchmarks, including Math Odyssey, AIME, and Olympiad- Bench. The study advances the application of LLMs in complex reasoning tasks and sets a foundation for future AI integration, enhancing decision-making ac- curacy and reliability in LLM-driven applications. Codes publicly accessible at github.com/trotsky1997/MathBlackBox.

Learn more:
Getting 50% (SoTA) on ARC-AGI with GPT-4o. You can just draw more samples – Redwood Research Blog
RYAN GREENBLATT. JUN 17, 2024
I recently got to 50%1 accuracy on the public test set for ARC-AGI by having GPT-4o generate a huge number of Python implementations of the transformation rule (around 8,000 per problem) and then selecting among these implementations based on correctness of the Python programs on the examples (if this is confusing, go to the next section)2. I use a variety of additional approaches and tweaks which overall substantially improve the performance of my method relative to just sampling 8,000 programs.
Predictions
- 70% probability: A team of 3 top research ML engineers with fine-tuning access to GPT-4o (including SFT and RL), $10 million in compute, and 1 year of time could use GPT-4o to surpass typical naive MTurk performance at ARC-AGI on the test set while using less than $100 per problem at runtime (as denominated by GPT-4o API costs).
- Note that typical naive MTurk performance is probably not 85% on the test set (the prior baseline is on the easier train set) and there is no known human baseline. (Perhaps performance is around 70%?)
- 35% probability: Under the above conditions, 85% on the test set would be achieved. It’s unclear which humans perform at >=85% on the test set, though this is probably not that hard for smart humans.
- 60% probability: If a next generation frontier LLM (e.g. GPT-5) was much better at basic visual understanding (e.g. above 85% accuracy on Vibe-Eval hard), using my exact method (with minor adaptation tweaks as needed) on that LLM would surpass typical naive MTurk performance.
- 30% probability: Under the above conditions, 85% on the test set would be achieved.
- 80% probability: next generation multi-model models (e.g. GPT-5) will be able to substantially advance performance on ARC-AGI.
Noam Brown: AI vs Humans in Poker and Games of Strategic Negotiation | Lex Fridman Podcast #344
LEX. What do you think is the breakthrough, or the directions of work, that will take us towards solving intelligence towards creating AGI systems?
LEX. What are the ideas for getting becoming more data efficient?
NOAM. I mean that’s that’s the trillion dollar question in AI today. I mean if you can figure out how to make AI systems more more data efficient then that’s a huge breakthrough. So nobody really knows right now.
2:19:57 – AGI
If an LLM solves this then we’ll probably have AGI – Francois Chollet
Dwarkesh Patel. 183K subscribers. 16K views 10 days ago
TRANSCRIPT:
DWARKESH. So suppose that it’s the case that in a year a multimodal model can solve Arc let’s say get 80% whatever the average human would get then AGI?
FRANCOIS. Quite possibly yes…
I think if you if you start so honestly what I would like to see is uh an llm type model solving Arc at like 80% but only trained on information that is not um explicitly trying to anticipate what it’s going to be in the AR test set but isn’t the isn’t the whole point of Arc that you can’t sort of it’s a new chart of type of intelligence every single time is the point so if Arc were perfect Flawless Benchmark it would be impossible to anticipate within the test set and you know Arc was released uh more than four years ago and so far it’s been resistant to memorization so I think it has uh to some extent passed a test of time but I don’t think it’s perfect I think if you try to make by hand uh hundreds of thousands of AR tasks and then you try to multiply them uh uh by programmatically generating variations and then you end up with maybe hundreds of millions of tasks uh just by brute forcing the task space there will be enough overlap between what you’re train on and what’s in the test set that you can actually score very highly so you know with enough scale you can always cheat if you can do this for every single thing that supposedly requires intelligence then what good is intelligence apparently you can just Brute Force intelligence if if the world if your life were athetic distribution uh then sure you could just bruteforce the space of possible behaviors could like you know the way we think about intelligence there are several metaphors SEL actives but one of them is you can think of intelligence as a past finding algorithm in future situation space like I don’t know if you’re familiar with game development like RTS game development but you have a map right and and you have it’s like a 2d 2D 2D map and um you have partial information about it like there is some fog of War on your map there are areas that you haven’t explored yet you know nothing about them and then there are areas that you’ve explored but um you only know how they were like in the past you don’t know how they like today and um and and now instead of thinking about Tod I think about the space of possible future situations that you might encounter and how they’re connected to each other intelligence is a past finding algorithm so once you set a goal it will tell you uh how to get there Optimum um but of course it’s it’s constrained by the information you have uh it it cannot pass fine in an area that you know nothing about it cannot also anticipate uh uh changes and um the the the thing is if you had complete information about the map uh then you could solve the pathf finding Problem by simply memorizing every possible path every mapping from uh point A to point B uh you could you could solve the problem with pure memory but where the reason you cannot do that in real life is because you don’t actually know what’s going to happen in the future life is Ever Changing I feel like you’re using words like memorization which we never use for human children if if like your kid learns to do algebra and then like now learns to do calculus you wouldn’t say they memorized Calculus if they can just solve any arbitrary algebraic problem you wouldn’t say like they’ve memorized algebra they say they’ve learned algebra humans are never really doing pure memorization or pure reasoning but that’s only because you’re semantically labeling when the human does the skill it’s a memorization when the exact same skill is done by the llm as you can measure by these bench marks and you can just like plug in any sort of math problem humans are doing the exact same as LM is doing which is just for instance I know if you learn to add numbers you’re memorizing an algorithm you’re memorizing a program and then you you can reapply it you are not synthesizing on the Fly uh the addition program so obviously at some point some human had to figure out how to do addition but like the way a kid learns it is not that they sort of out from the accents of SE Theory how to do addition I think what you learn in school is mostly memorization right so my claim is that listen these models are vastly underparameterized relative to how many flops or how many parameters you have in the human brain and so yeah they’re they’re not going to be like coming up with new theorems like the smartest humans can but most humans can’t do that either um what most humans do it sounds like a similar to what you’re calling memorization which is memorizing skills or memorizing um you know uh techniques that you’ve learned and so it sounds like it’s compatible in your tell me if this is wrong is it compatible in your world if like all the remote workers are gone but they’re doing skills which we can potentially make synthetic data of so we record everybody’s screen and every single remote worker screen we sort of understand the skills they’re performing there and now we’ve trained a model that can do all this all the remote workers are unemployed we’re generating trillions of dollars of economic activity from Mii uh remote workers in that world is are we still in the memorization regime so sure uh with memorization you can automate almost anything as long as it’s it’s a static distribution as long as you don’t have to deal with change
AI Won’t Be AGI, Until It Can At Least Do This (plus 6 key ways LLMs are being upgraded)
AI Explained. 266K subscribers. 128K views. 18 June 2024
The clearest demonstration yet of why current LLMs are not just ‘scale’ away from general intelligence. First, I’ll go over the dozen ways AI is getting murky, from dodgy marketing to tragedy-of-the-commons slop, Recall privacy violations to bad or delayed demos. But then I’ll touch on over a dozen papers – and real-life deployments, of LLMs, CNNs and more – making the case that we shouldn’t throw out the baby with the bathwater. Crucially, I’ll cover 6 key approaches that are being developed to drag LLMs toward AGI. this video will hopefully, at the very least, leave you much better informed on the current landscape of AI.
REF LINKS. ARC-prize: https://arcprize.org/?task=3aa6fb7a ChatGPT is Bullshit: https://link.springer.com/article/10…. Apple Cook Interview: https://www.washingtonpost.com/opinio… AI Slop: https://taplio.com/generate-linkedin-… https://www.npr.org/2024/05/14/125107… OpenAI Erotica: https://www.theguardian.com/technolog… AI Toothbrush: https://www.oralb.co.uk/en-gb/product… Recall Hackable: https://www.wired.com/story/microsoft… Murati: ‘Few Weeks’:  • Introducing GPT-4o Medical Studies: https://x.com/JeremyNguyenPhD/status/… BeMyEyes Demo: • Be My Eyes Accessibility with GPT-4o BrainoMix: https://www.ncbi.nlm.nih.gov/pmc/arti… https://www.gov.uk/government/news/ar… Chollet Clips and Interview: • Francois Chollet On LLMs w/ Active In… • Francois Chollet recommends this meth… • Francois Chollet – LLMs won’t lead to… Gartner Hype Cycle: https://s7280.pcdn.co/wp-content/uplo… Jack Cole: https://x.com/Jcole75Cole/status/1787… Methods: https://lab42.global/community-interv… https://lab42.global/community-model-… Ending Animal Testing – GAN: https://www.nature.com/articles/s4146… https://www.bbc.co.uk/news/articles/c… Virtual Rodent: https://x.com/GoogleDeepMind/status/1… Google AI Overviews: https://www.nytimes.com/2024/06/01/te… Noam Brown Optimism: https://x.com/polynoamial/status/1801… MLC Human-like Reasoning: https://www.nature.com/articles/s4158… Many Shot Google Deepmind: https://arxiv.org/pdf/2404.11018 Automated Process Supervision: https://arxiv.org/pdf/2406.06592 No Zero-shot Without Exponential Data: https://arxiv.org/pdf/2404.04125 Prof. Rao Paper 1: https://openreview.net/pdf?id=X6dEqXIsEW DrEureka: https://eureka-research.github.io/dr-… AlphaGeometry: https://deepmind.google/discover/blog… Graph Neural Networks Joint: https://arxiv.org/pdf/2406.09308 Terence Tao: Tacit Data: https://www.scientificamerican.com/ar… Mira Murati on Models: https://x.com/tsarnick/status/1801022… Chollet Tweet: https://x.com/fchollet/status/1801780… Non-hype Newsletter: https://signaltonoise.beehiiv.com/ GenAI Hourly Consulting: https://www.theinsiders.ai/
• Introducing GPT-4o Medical Studies: https://x.com/JeremyNguyenPhD/status/… BeMyEyes Demo: • Be My Eyes Accessibility with GPT-4o BrainoMix: https://www.ncbi.nlm.nih.gov/pmc/arti… https://www.gov.uk/government/news/ar… Chollet Clips and Interview: • Francois Chollet On LLMs w/ Active In… • Francois Chollet recommends this meth… • Francois Chollet – LLMs won’t lead to… Gartner Hype Cycle: https://s7280.pcdn.co/wp-content/uplo… Jack Cole: https://x.com/Jcole75Cole/status/1787… Methods: https://lab42.global/community-interv… https://lab42.global/community-model-… Ending Animal Testing – GAN: https://www.nature.com/articles/s4146… https://www.bbc.co.uk/news/articles/c… Virtual Rodent: https://x.com/GoogleDeepMind/status/1… Google AI Overviews: https://www.nytimes.com/2024/06/01/te… Noam Brown Optimism: https://x.com/polynoamial/status/1801… MLC Human-like Reasoning: https://www.nature.com/articles/s4158… Many Shot Google Deepmind: https://arxiv.org/pdf/2404.11018 Automated Process Supervision: https://arxiv.org/pdf/2406.06592 No Zero-shot Without Exponential Data: https://arxiv.org/pdf/2404.04125 Prof. Rao Paper 1: https://openreview.net/pdf?id=X6dEqXIsEW DrEureka: https://eureka-research.github.io/dr-… AlphaGeometry: https://deepmind.google/discover/blog… Graph Neural Networks Joint: https://arxiv.org/pdf/2406.09308 Terence Tao: Tacit Data: https://www.scientificamerican.com/ar… Mira Murati on Models: https://x.com/tsarnick/status/1801022… Chollet Tweet: https://x.com/fchollet/status/1801780… Non-hype Newsletter: https://signaltonoise.beehiiv.com/ GenAI Hourly Consulting: https://www.theinsiders.ai/